This post provides an introduction in the preparation of the record linkage model. Given the example of the previous post, the easiest approach is to import data in a spreadsheet software (Microsoft Excel or Libre Office will do just fine) and to actually start record linkage.
Let’s prepare the file in the CSV format like:
ID,Name,Address,Company,Products
1,Joe Smith,"1234 56 St. New York, NY",Newyorkonics,"SuperProd,MegaProd"
2,Alice Thompson,"4789 Woodward Ave. Detroit, MI",Detroitics,"MegaProduct,TeraProd"
3,James Jones,"4789 Woodward Ave. Detroit, MI",Detroitics,GigaProd
4,Ramkrishna (Ram) Kumar,"New Orchard Road, Armonk, New York 10504 ",IBM,"GigaProduct, PetaProduct"
5,Jackob Jones," One Microsoft Way Redmond, WA 98052-7329",Microsoft,Peta Product
6,Mary Barry,"Renaissance Center, Detroit",GM,Tera product
7,James (Jim) Stephenson,"One Ford Way, Dearborn, MI 48126",Ford,Petaprod
8,Alicia Shepard,"1234 56 St. New York, NY",Newyorkonics,???
9,Michael Taylor,"Classified, Bethesda, MD",Lockheed Martin,TeraProd
10,Jim Jones,"1234 Woodward Ave. Detroit, MI","Moonlighting, Inc",MegaProd
and:
ID,Name,Address,Company,Products
1,Joel Smith," New York, NY",New York-onics,"MegaProduct,SuperProd"
2,Alicia Thomson,4789 Woodward Avenue Detroit,Detroitics,"MegaProd,TeraProd"
3,James Jones,"1234 Woodward Ave. Detroit , MI",Moonlighting,Mega-Prod
4,Ram Kumar,"New Orchard Road, Armonk, NY",International Business Machines, PetaProduct
5,Jack Jones, One Microsoft Way Redmond,Microsoft USA,PetaProd
6,Mary Kerry,"12345 Michigan Ave, Chicago IL",Chicagonics,MegaProd
7,Mary Barry,"GM Renaissance Center, Detroit, MI 48243",General Motors,"TeraProd,SuperProd"
8,James Stephenson,"One Ford Way, Dearborn, MI",Ford,Petaprod
9,Al Shepard," New York, NY",Newyorkonics,"SuperProd,MegaProd"
10,Mike Taylor,Unknown,Lockheed-M,Tera Product
11,James Jones,"4789 Woodward Ave. Detroit , MI",Detroitics,"GigaProd,MegaProd"
The goal of the exercise is to establish a relation between the identifiers of the two sets, both provided on the first column.
We will prepare the model of the record linkage, which is an XML file describing the relations between the entities. The model contains the connections to the databases, the entities to be linked (left to right) and the rules of linking. The basic anatomy of the file is shown below:
<?xml version="1.0" encoding="UTF-8" ?>
<matchdocument>
<dbconnections>
.......
</dbconnections>
<entities>
<left>
.......
</left>
<right>
.......
</right>
</entities>
<matches>
....
</matches>
</matchdocument>
The file contains the model of the linkage. The first section describes the set of database connections to retrieve data from:
<dbconnections local="local">
<drivers>
<driver>org.postgresql.Driver</driver>
<driver>org.relique.jdbc.csv.CsvDriver</driver>
</drivers>
<connections>
<connection id="local" url="jdbc:postgresql://127.1:5432/match2"
user="postgres" password="***" dialect="pgsql"/>
<connection id="testdata" url="jdbc:relique:csv:data/test1" dialect="csvjdbc">
</connection>
</connections>
</dbconnections>
Each connection is described by its URL, user name and password. The data can be read from any connection. The local connection, provided by the attribute of the <dbconnections> is where the temporary data and linkage results are stored. Reading data from CSV files is being performed using the same approach as data being retrieved from a database.
The next section modes the entities involved in the linkage. Each entity from the left section can be linked to an entity on the right section, as following:
<entities>
<left>
<entity name="sales" conn="testdata" shorttitle="name" title="name">
<query><![CDATA[
select id,name from list1
]]>
</query>
<fields>
<field name="id" alias="id_sales" cardinality="ONE" type="integer" />
<field name="name" cardinality="ONE" type="text" />
</fields>
<keys>
<key name="id" />
</keys>
</entity>
</left>
<right>
<entity name="support" conn="testdata" shorttitle="name"
title="name" >
<query><![CDATA[
select id,name from list2
]]>
</query>
<fields>
<field name="id" alias="id_support" cardinality="ONE" type="integer" />
<field name="name" cardinality="ONE" type="text" />
</fields>
<keys>
<key name="id" />
</keys>
</entity>
</right>
</entities>
Each entity has a query and a set of fields, extracted from the query.
An entity can be defined by a compound primary key, composed of more than one field. Also, there are two special fields called title and shorttitle, used for display and interactive operations.
For exemplification purposes, only the name field is extracted from the provided CSV data.
The next section describes the matching rules. To be succint, only a single rule is defined, the exact name similarity.
<matches>
<match name="matchperson" left="sales" right="support" lcard="ZEROONE"
rcard="ZEROONE" >
<rules>
<rule name="byname" lfield="name" rfield="name" type="EQUALITY" />
</rules>
</match>
</matches>
Multiple <match> blocks can be created, in order to connect all of the entities defined in the <left> and <right> elements of <entities>. The lcard and rcard attributes define the cardinality of the record linkage. Each side can have a value of ZEROONE,ONE,ONETON or ZEROTON. The cardinality defines how many linkages can be performed with one element. I will detail this topic in a dedicated post.
Each match will have one or more <rule> elements. They define the criteria used to match the entities. In our example, we only compare the name fields of the two entities, and request they to be equal.
Let’s run the record linkage. Since we only have 10 records, the execution time shall be under 2-3 seconds. The output can be either inspected visually, or it is provided as a linkage table below:

Also the SQL result shows that the record linkage identifies two record links. The identifiers of the primary keys of the two linked entities are the names provided by the alias attribute of the fields.
match2=# select * from matchperson;
id_sales | id_support
----------+------------
3 | 3
6 | 7
(2 rows)
The issue now is that only matched names are displayed, which is not of help. It is desirable to extend the display, so that the whole record is been shown. To accomplish this we have to change the query originating the data source. The new entity code is changed as following:
<left>
<entity name="sales" conn="testdata" shorttitle="name" title="name2">
<query><![CDATA[
select id,name , '<B>'+htmlfy(name)+'</B> <SMALL style=color:blue>'+htmlfy(address)+'</SMALL><BR><I>'+htmlfy(company)+'</I> <SMALL>'+htmlfy(products)+'</SMALL>' as name2 from list1
]]>
</query>
<fields>
<field name="id" alias="id_sales" cardinality="ONE" type="integer" />
<field name="name" cardinality="ONE" type="text" />
<field name="name2" cardinality="ONE" type="text" />
</fields>
<keys>
<key name="id" />
</keys>
</entity>
</left>
The shorttitle of the entity remains name, but the title gets a larger value, a which is a concatenation of all available data fields.
The same change will apply for the right entity. In a real-life record linkage environment the entities do not have the same structure, hence the expression used as description of entities will vary widely.
The htmlfy function has to be defined as a stored procedure on the database level, and it shall escape any HTML control character encountered in the text. For this case, since we use a CSV JDBC driver, the function is actually defined at the driver level, though the following connection entry:
<connection id="testdata" url="jdbc:relique:csv:data/test1"
dialect="csvjdbc">
<property name="function.htmlfy"
value="org.apache.commons.lang3.StringEscapeUtils.escapeHtml4(String)" />
</connection>
Running the linkage again, the following linkage report can be inspected:

It can be clearly seen that the first linkage is not a good match; both the address, the company and the products are different. It may be possible that multiple names from the left will match multiple names from the right. Due to our constraint of linking one or none, only one of the choices has been considered. Since equality is dichotomic, without a similarity measure, the decision of taking one record was merely random. Let us allow any number of linkages to be discovered:
<match name="matchperson" left="sales" right="support" lcard="ZEROTON"
rcard="ZEROTON" >
...
</match>

Once this report has been displayed, it turns clear that we have the same person stored twice in the database, once for the home address and company, and second for the employer. In this point, we can either mismatch the first link, validate the second link or both.
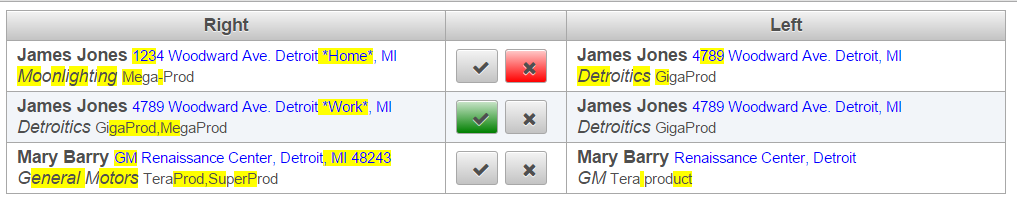
With this changes done, the next run will properly identify the record linkages.
With this post I have just scratched the surface of the capabilities delivered by my record linkage tool. In the next posts I will describe the heuristic matching capabilities, as well how to associate together more than one entity linkage rule.