 Most of the record linkage techniques operate on two tables and define set of association rules. Is this the limit of what can be done?
Well, my software goes beyond independent tables, exploring the relational dimension of data. This post is about matching sets of
records associated to one data record.
Most of the record linkage techniques operate on two tables and define set of association rules. Is this the limit of what can be done?
Well, my software goes beyond independent tables, exploring the relational dimension of data. This post is about matching sets of
records associated to one data record.
The structured data is always organized by a relational model, meaning that records usually points to one or more
records from different tables. There is a virtual link back, as the pointed record can be associated to the initial record.
This way, two types of relations between items can be exploited in record linkage. Considering the table A
and a table B endowed with a foreign key to A, one (or none) record of B points to exactly one record in
A and virtually one record in A can refer multiple records of B.
In the context of record linkage, let us consider on one side the tables A and B from above to be linked to
A' and B', with the same type of relation.
The relations observed are of two types:
-
One-to-many computes a score on a pair of two records from
AandA', given the already computed scores between the corresponding records inBandB'. -
Many-to-one provides a rule of similarity computed on a pair of records in
BandB'considering the score of the referred records inAandA'.
The relation is just one criterion of linkage, the records may benefit of additional comparison criteria.
The following example is used to illustrate the concept.
The two tables A and A' are defined as:
ID,Name
1,Group 1
2,Group 2
3,Group 3
4,Group 4
and
ID,Name
1,Group one
2,Second group
3,Third Group
4,Fourth Group
On purpose, no direct similarity criterion can be imagined for the two groups, assuming no Natural Language Processing is being performed and also ignoring the identical IDs used for cross check.
The two groups provided above are referred by a number of group members, defined as:
ID,GID,Col
101,1,Red
102,1,Yellow
103,1,Pink
104,2,Red
105,2,Blue
106,2,Black
207,2,White
301,3,Burgundy
302,3,Magenta
303,3,Orange
304,3,Cyan
401,4,Khaki
402,4,Green
and
ID,GID,Col
1,1,Red
2,1,Yellow
3,1,Pink
4,2,Red
5,2,Blue
6,2,White
7,2,Dark Gray
8,3,Magenta
9,3,Blue
10,3,Orange
11,3,Burgundy
12,4,Khaci
13,4,Green
In the second set of tables, GID is the reference to the respective group.
To be able to display the relational data, I used StelsCSV JDBC driver .
Simply for matching, the Relique JDBC driver will suffice, but
in this case it will not be possible to show the groups with their composing elements, achieved
with the help of GROUP_CONCAT function.
Data import is symmetric and similar to the previous examples, with the exception of the fkeys tag, which models the relation between entities:
<?xml version="1.0" encoding="UTF-8" ?>
<matchdocument>
<dbconnections local="local">
<drivers>
<driver>org.postgresql.Driver</driver>
<driver>jstels.jdbc.csv.CsvDriver2</driver>
</drivers>
<connections>
<connection id="testdata" url="jdbc:jstels:csv:data/rela/?separator=," dialect="generic"/>
<connection id="local" url="jdbc:postgresql://127.1:5432/rel"
user="postgres" password="r" dialect="pgsql" />
</connections>
</dbconnections>
<entities>
<left>
<entity name="gr1" conn="testdata" shorttitle="name" title="name2">
<query><![CDATA[
select l.id,l.name,
concat('<B>',name,'</B> <I>', l.id, '</I>, <small>',GROUP_CONCAT(c.col),'</small>') as name2
from groups1 l join content1 c on l.id=c.GID
group by l.id,l.name
order by l.id
]]>
</query>
<fields>
<field name="ID" alias="id_gr_left" cardinality="ONE" type="char(7)" />
<field name="name" cardinality="ONE" type="text" />
<field name="name2" cardinality="ONE" type="text" />
</fields>
<keys>
<key name="ID" />
</keys>
</entity>
<entity name="content1" conn="testdata" shorttitle="col"
title="name2">
<query><![CDATA[
select c.ID,c.GID,c.Col,
concat(c.col,' - ', c.ID,' - ', c.GID,' - ', l.name) as name2
from content1 c left join groups1 l on l.id=c.GID
order by c.id
]]>
</query>
<fields>
<field name="ID" alias="id_content_left" cardinality="ONE"
type="integer" />
<field name="col" cardinality="ONE" type="text" />
<field name="GID" cardinality="ONE" type="text" />
<field name="name2" cardinality="ONE" type="text" />
</fields>
<keys>
<key name="ID" />
</keys>
<fkeys>
<fkey name="content2group" target="gr1" fields="GID" />
</fkeys>
</entity>
</left>
<right>
<entity name="gr2" conn="testdata" shorttitle="name" title="name2">
<query><![CDATA[
select l.id,l.name,
concat('<B>',name,'</B> <I>', l.id, '</I>, <small>',group_concat(c.col),'</small>') as name2
from groups2 l join content2 c on l.id=c.GID
group by l.id,l.name
order by l.id
]]>
</query>
<fields>
<field name="ID" alias="id_gr_right" cardinality="ONE" type="char(7)" />
<field name="name" cardinality="ONE" type="text" />
<field name="name2" cardinality="ONE" type="text" />
</fields>
<keys>
<key name="ID" />
</keys>
</entity>
<entity name="content2" conn="testdata" shorttitle="col"
title="name2">
<query><![CDATA[
select c.ID,c.GID,c.Col,
concat(c.col,' - <small>', c.ID,' - ', c.GID,'</small> - ', l.name) as name2
from content2 c left join groups2 l on l.id=c.GID
order by c.id
]]>
</query>
<fields>
<field name="ID" alias="id_content_right" cardinality="ONE"
type="integer" />
<field name="col" cardinality="ONE" type="text" />
<field name="name2" cardinality="ONE" type="text" />
<field name="GID" cardinality="ONE" type="char(7)" />
</fields>
<keys>
<key name="ID" />
</keys>
<fkeys>
<fkey name="content2group" target="gr2" fields="GID" />
</fkeys>
</entity>
</right>
</entities>
We introduce the linkage rule of type RELATION_SIMILARITY.
The relation similarity does not use fields, but a pair of left and right relations which
are scored similarly to field values. The two relations shall have the same cardinality.
The
rule bygroupname has been introduced simply to generate the candidates for
group matching. There are better techniques of generated the candidates (called blocking in the literature), but for now we focus on the relation matching only.
<matches>
<match name="matchgroup" left="gr1" right="gr2" lcard="ZEROONE"
rcard="ZEROONE">
<rules>
<rule name="bygroupname" lfield="name" rfield="name" type="STR_JARO_WRINKLER">
<score alpha="0.5" beta="0.5" thresholdtype="ONE" threshold="0.5"
confidenceMode="LINEAR" />
</rule>
<rule name="matchcontents" lrelation="content2group" rrelation="content2group"
type="RELATION_SIMILARITY">
<score alpha="0.9" beta="0.9" thresholdtype="ONE" threshold="0.70"
confidenceMode="LINEAR" thresholdValue="PERCENTILE" />
</rule>
</rules>
</match>
<match name="matchcontent" left="content1" right="content2"
lcard="ZEROONE" rcard="ZEROONE">
<rules>
<rule name="byname" lfield="col" rfield="col" type="STR_JARO_WRINKLER">
<score alpha="0.9" beta="0.9" thresholdtype="ONE" threshold="0.85"
confidenceMode="LINEAR" />
</rule>
<rule name="matchgroup" lrelation="content2group" rrelation="content2group"
type="RELATION_SIMILARITY">
<score alpha="0.9" beta="0.95" thresholdtype="ONE" threshold="0.60"
confidenceMode="LINEAR" thresholdValue="PERCENTILE" />
</rule>
</rules>
</match>
</matches>
The results are quite impressive. All the groups as well as the changed colors were associated properly!
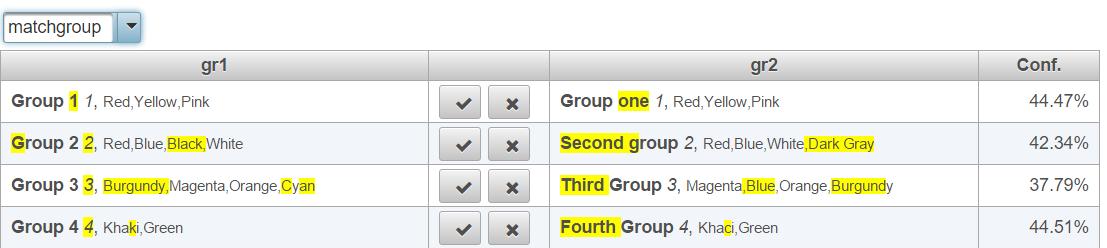
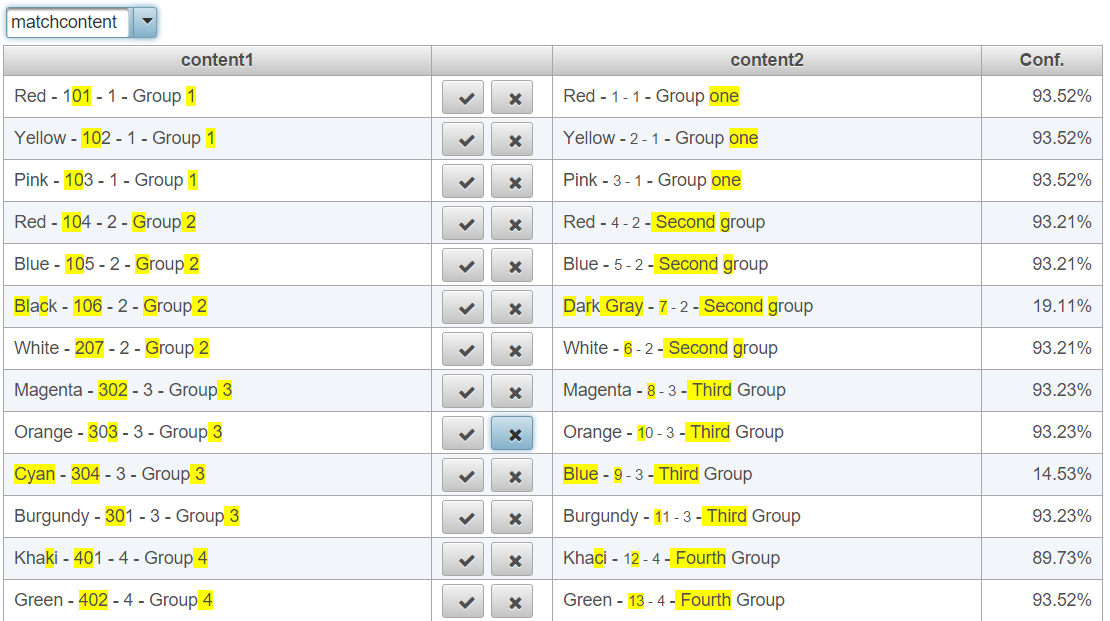
The data set is too small to establish a 100% correct linkage claim. I used it just to illustrate the capability of performing record linkage on structured and relational data, relying upon the references between the records rather than on their data payload. As you can notice, the two data sets do not share any common data, such as an already linked set of elements for the groups. The linkage is performed between both the groups and their elements.